埋点 SDK 数据采集软件架构
背景
在服务近 2000 家客户的过程中,客户对埋点采集 SDK 提出各式各样的需求。
从需求的类型来看大致分成两种:安全你合规以及功能类需求。
安全合规类型
- 禁止特定属性上报
- 禁止特定 API 进行调用
- 源码里禁止特定关键词
- 个人信息匿名化
- 数据采集、存储、传输加密
功能类型
- 用户行为数据精细化采集,如点击、浏览、曝光
- 支持多实例,同一个 App 可将数据发送到不同地址
- 配合分析以及营销相关数据采集,如推送、弹窗、可视化埋点
从端的角度来看,数据采集分成客户端以及服务端
| 端 | 系统 |
|---|---|
| 客户端 | Android/iOS/Web/小程序/三方框架/游戏引擎 |
| Paragraph | Java/PHP/Ruby/Python/Lua |
对于什么时候应该用客户端埋点,什么时候使用服务端埋点,遵循一个原则:永远优先从服务端采集,只有当服务端采集不到,才考虑在客户端采集。
埋点系统软件架构原则
开放性
足够的开放,数据采集、存储、传输全过程是可以任意定制的,比如加密算法定制、采集数据定制、上报的数据格式、数据传输过程中 SSL 证书配置等。
稳定性
一个优秀的埋点 SDK ,在任何场景下不应该影响到宿主容器应用,比如性能以及 crash 问题。
数据准确性
由于网络环境以及用户行为不确定性和设备的多样性,SDK 需要尽可能保证数据不重不漏。
SDK 技术架构
数据存储和传输策略
服务端 SDK 相对于客户端 SDK 来说简单很多,这里以客户端举例来看:
不同于服务端,移动设备上的资源是非常有限的,采取实时上报的方式势必会造成 App 整体性能的下降,如何平衡性能与数据上报的时效性是 SDK 需要面临的一个挑战。
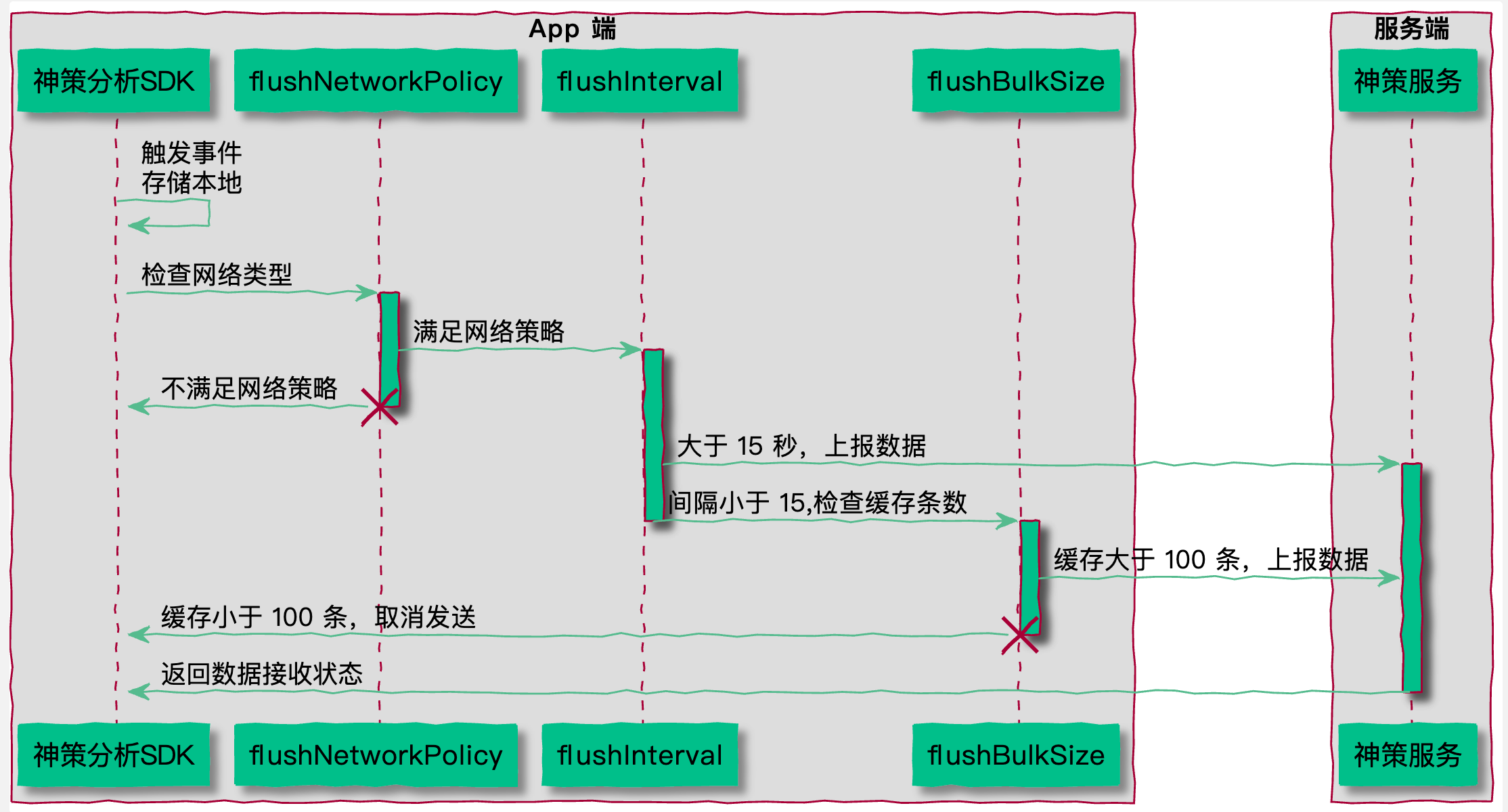
目前 SDK 中使用的数据上报策略是事件触发后不立即上报,而是先将事件缓存在本地,然后满足一定的条件再进行上报。
SDK 每次触发事件时会检查如下条件,用于判断是否向服务端上报数据:
1. 当前网络是否符合发送策略 flushNetworkPolicy(默认 3G、4G、5G、WiFi);
2. 与上次发送的时间间隔是否大于指定的时间间隔 flushInterval(默认 15 秒);
3. 本地缓存的事件条数是否大于最大缓存事件数 flushBulkSize(默认 100 条)。
只有 1、2 或者 1、3 满足时,SDK 才会发送数据。当然,为了满足不同的需求,可以通过修改 flushNetworkPolicy、flushInterval、flushBulkSize 的值来控制事件上报。
对于 Web 以及小程序而言,和 Android & iOS 相比最大的区别在于缓存的稀缺的,通常用 localstorage
来进行存储,一般 200-300 条就会满,所以需要更频繁的去发送,确保数据不会漏掉。
极端场景适配
典型场景如退到后台和强杀应用,这两个场景,需要针对性进行处理,确保数据尽快的存储和发送。
技术架构
需要考虑以下几个模式的应用:生产消费者架构,事件队列。
依照数据流处理过程,可将模块抽象为数据采集拼装、数据入库、数据传输。
Q&A
在什么场景下,数据可能会发生丢失?
以下场景下会可能发生丢失:
- SDK 本地缓存满了,达到上限
- Web SDK 采用实时发送模式,网络环境较差或者浏览器强杀则丢失
- App 卸载和浏览器清除数据
- 数据未入库前 App 强杀
上述场景是由 App 或浏览器的用户行为发起,在极端环境下产生的数据丢失。这种现象从理论上来看无法真正消除,只能尽可能去保证数据不丢。
如何保障数据不重不漏?
- SDK 端持久化缓存和数据重试发送策略
- 本地数据库(持久化)
- 合理的上报策略(数据条数以及数据发送间隔)
- 异常场景优化(退后台、App 强杀)
- 重试发送(根据状态码判定上报状态)
- SDK 优秀架构(生产消费者模型)
- 服务端状态回传以及去重机制
总结
以上就是埋点采集系统技术架构上需要考虑的点,埋点是一件看起来简单,实际很复杂的一件事情。随着系统以及合规政策的日新月异,埋点也需要不断适配。只有构建好了足够坚实的数据根基,才能有效支持上层的数据分析以及运营。